Abstract
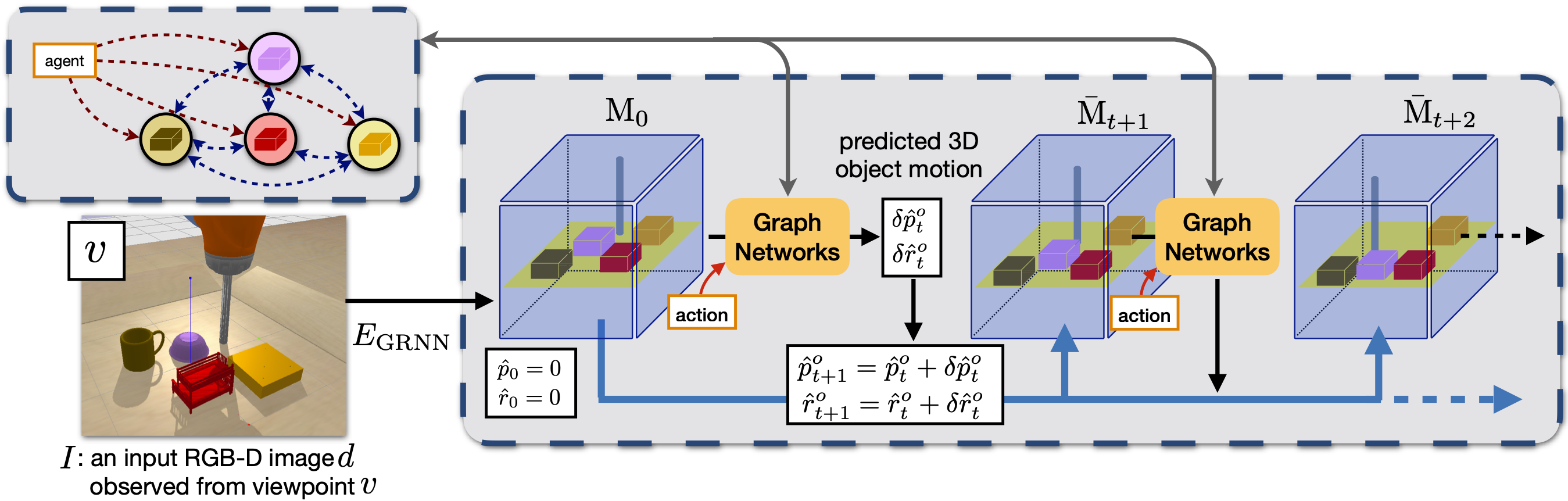
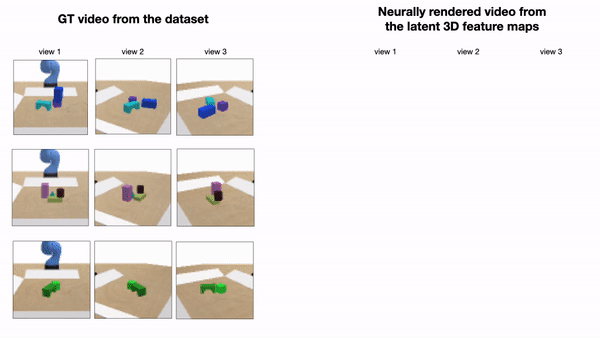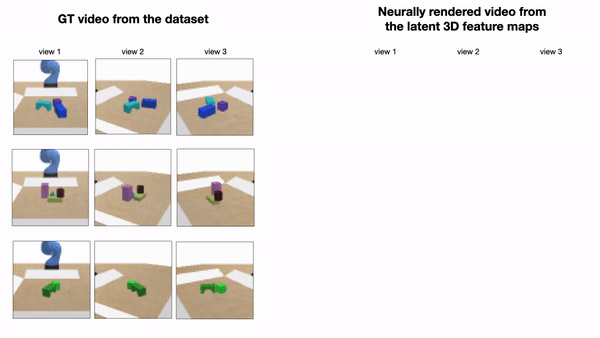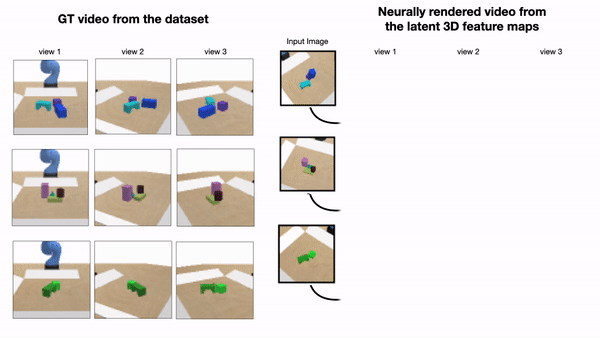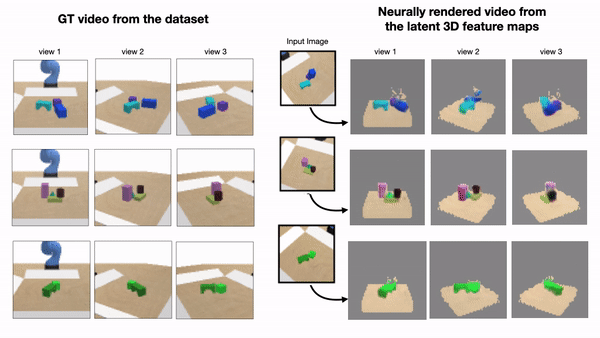
Humans can effortlessly predict how a scene changes approximately as a result of their actions. Such predictions, which we call mental simulations, are carried out in an abstract visual space that is not tied to a particular camera viewpoint. Inspired by such capability to simulate the environment in a viewpoint- and occlusion- invariant way, we propose a model of action-conditioned dynamics that predicts scene changes caused by object and agent interactions in a viewpoint-invariant 3D neural scene representation space, inferred from RGB-D videos. In this 3D feature space, objects do not interfere with one another and their appearance persists across viewpoints and over time. This permits our model to predict future scenes by simply "moving" 3D object features based on cumulative object motion predictions, provided by a graph neural network that operates over the object features extracted from the 3D neural scene representation. Moreover, our 3D representation allows us to alter the observed scene and run conterfactual simulations in multiple ways, such as enlarging the objects or moving them around, and then simulating the corresponding outcomes. The mental simulations from our model can be decoded by a neural renderer into 2D image projections from any desired viewpoint, which aids interpretability of the latent 3D feature space. We demonstrate strong generalization of our model across camera viewpoints and varying number and appearances of interacting objects, while also outperforming multiple existing 2D models by a large margin. We further show effective sim-to-real transfer by applying our model trained solely in simulation to a pushing task in a real robotic setup.
|